


Google lansat Gemma 4, cea mai inteligentă familie de modele open-source dezvoltată de companie până în prezent. Această nouă iterație este concepută special pentru a gestiona sarcini complexe de raționament și fluxuri de lucru tip „agentic”, oferind un raport de inteligență per parametru fără precedent. Lansarea vine ca răspunsul la cerințele comunității de dezvoltatori, beneficiind de o bază solidă de peste 400 de milioane de descărcări ale generațiilor anterioare Gemma 3 și a unui ecosistem vast cu peste 100.000 de variante create de utilizatori.
Spre deosebire de modelele tradiționale de chat, Gemma 4 este optimizat pentru a depăși rolul de simplu chatbot, integrând capacități de logică complexă. Modelele sunt construite pe baza acelei tehnologii și cercetări care stau la baza Gemini 3, oferind dezvoltatorilor o combinație puternică între instrumentele proprietare și cele deschise. Această abordare permite rularea unor modele extrem de capabile direct pe hardware-ul local, reducând dependența de infrastructuri cloud masive pentru sarcini specifice.
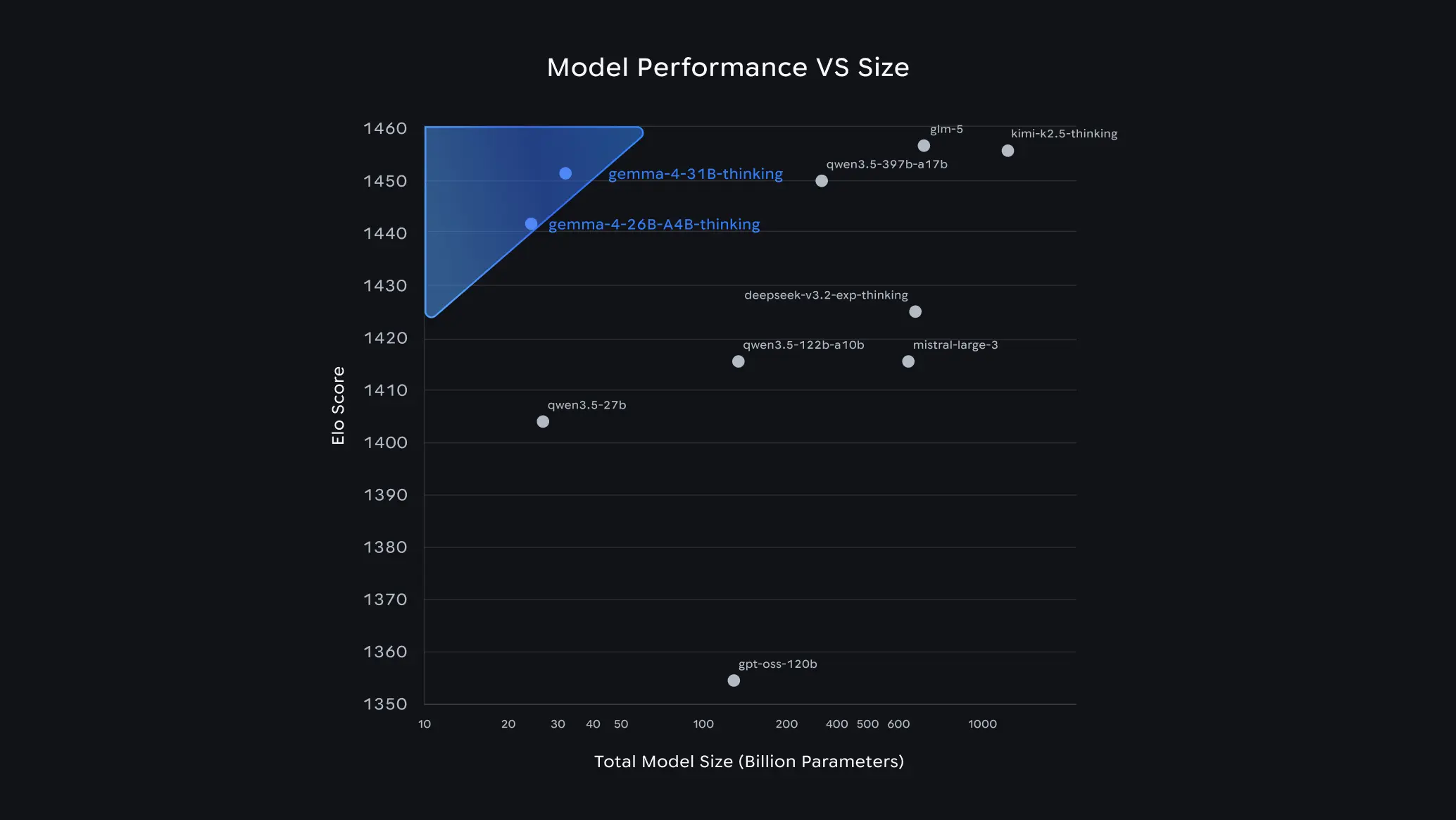
O particularitate importantă a acestei generații este diversitatea dimensiunilor disponibile, adaptate pentru diferite scenarii de utilizare. Google a lansat patru variante: E2B (Effective 2B) și E4B (Effective 4B) pentru dispozitive edge, precum și modelele de 26B Mixture of Experts (MoE) și 31B Dense pentru stații de lucru. Modelul de 31B a urcat deja pe locul 3 în clasamentul Arena AI, demonstrând că poate concura cu modele de dimensiuni mult mai mari, reducând astfel costurile de hardware necesare pentru performanțe de top.
În ceea ce privește funcționalitățile tehnice, Gemma 4 introduce suport nativ pentru multimodalitate. Toate modelele pot procesa imagini și video, fiind eficiente în sarcini precum recunoașterea optică a caracterelor (OCR) sau analiza graficelor. Mai mult, variantele mici (E2B și E4B) includ suport pentru audio, facilitând recunoașterea vorbirii direct pe dispozitive mobile sau IoT, cum ar fi telefoanele Android sau Raspberry Pi, cu o latență minimă.
Capacitatea de procesare a contextului a fost semnificativă crescută pentru a permite analiza documentelor lungi sau a întregilor baze de cod. Modelele destinate dispozitivelor mobile gestionează o fereastră de context de 128.000 de token-uri, în timp ce modelele mai mari ajung până la 256.000. De asemenea, Gemma 4 suportă peste 140 de limbi internaționale. Pentru programatori, modelul oferă suport pentru generarea de cod offline, transformând computerul personal într-un asistent de programare local.
Gemma 4, pe scurt:
- Hardware compatibil: NVIDIA H100, GPU-uri Blackwell, GPU-uri AMD (prin ROCm), TPU Trilliuim și Ironwood
- Variante: Gemma 4 E2B (Effective 2B), Gemma 4 E4B (Effective 4B), Gemma 4 26B MoE (Mixtrue of Experts), Gemma 4 31B Dense
- Fereastră context: 128K tokens (modele edge) și până la 256K tokens (modele mari)
- Capabilități multimedia: Procesare video și imagini (toate); input audio (doar E2B și E4B)
- Suport lingvistic: Peste 140 de limbi
- Licență: Apache 2.0 (comercial permisivă)
- Software/Ecosistem: Google AI Studio, Google AI Edge Gallery, Android AICore
Un aspect crucial este adoptarea licenței Apache 2.0, care oferă dezvoltatorilor o flexibilitate totală și suveranitate digitală. Potrivit declarațiilor companiei, această decizie a fost luată pentru a elimina barierele restrictive, permițând controlul complet asupra datelor și infrastructurii. Modelele pot fi implementate atât on-premises, cât și în cloud, oferind securitate sporită pentru organizațiile care au nevoie de transparență totală asupra modului în care funcționează AI-ul.
Pentru implementare, Google a asigurat compatibilitatea cu cele mai populare instrumente din industrie, inclusiv Hugging Face, vLLM, llama.cpp și Ollama. Dezvoltatorii pot începe testarea rapid prin Google AI Studio sau pot adapta modelele folosind Vertex AI și Google Colab. Pentru cei care doresc scalabilitate maximă, Google Cloud oferă servicii de servere accelerate cu procesoare Tensor proprietare.