Deși mulți consideră că plăcile video precum NVIDIA GeForce RTX 5080 sunt gândite doar pentru gaming, realitatea este că cele mai mari îmbunătățiri pe care le-au adus comparativ cu generația trecută se regăsesc pe zona de AI. Și cum am în PC o astfel de matahală, am zis că este un moment numai bun să o pun la treabă și-n alte sarcini în afară de gaming 4K.
Bine, acum îndeletnicirile mele în domeniul inteligenței artificiale sunt limitate și cel mai mult am interacționat cu boți din ăștia precum Gemini și Co-Pilot. Așa că am decis să-mi încep călătoria plecând de aici. Sarcina mea pe astăzi? Să instalez un LLM local pe care să-l hrănesc cu informații, ca mai apoi să îmi fie de ajutor la munca de research pentru diferitele articole și videouri pe care le scriu.
Primii pași spre inteligența nemărginită
Înainte de a porni la treabă este important să ținem cont de specificațiile sistemului nostru. Cea mai importantă componentă aici este placa video, iar cu o NVIDIA GeForce RTX 5080 de 16GB în PC sunt sigur că o să am o experiență ok. În principiu, cam toate plăcile din familia GeForce RTX 50 ar trebui să se descurce bine în sarcini AI – evident, capacitatea de VRAM contează mult, astfel recomand minim 16GB pentru modele locale. Restul configurației conține un procesor AMD Ryzen 7 9800X3D, alături de 48GB de memorie RAM. Ah da, și de preferat să aveți mereu driverele actualizate la zi pentru că includ optimizări de fel și chip.
Acum trebuie doar să-mi dau seama cum se instalează nebuniile astea. Așa că am intrat pe blog-ul NVIDIA dedicat tehnologiilor AI care rulează pe plăcile lor. Aici am aflat că cei de la OpenAI tocmai au lansat două modele noi numite gpt-oss-20b și gpt-oss-120b. Acestea se întâmplă să fie și primele modele NVFP4 compatibile cu plăcile NVIDIA GeForce RTX.
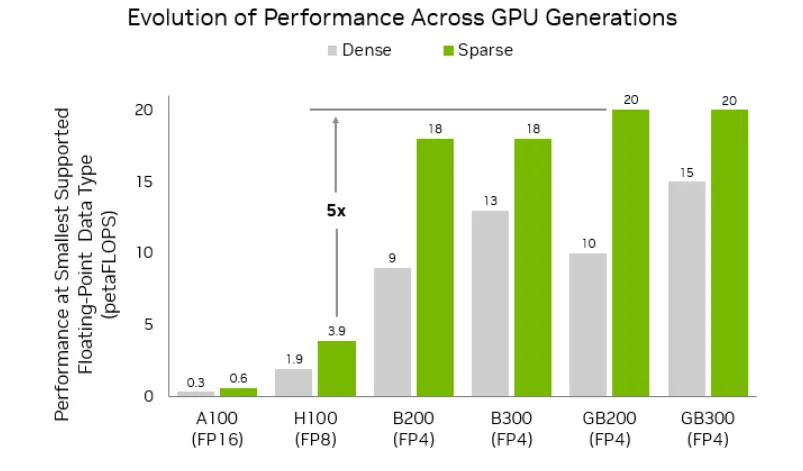
Și-acum să traducem chineza asta tech în ceva ce puteți înțelege cu toții: numele NVFP4 indică nivelul de cuantizare folosit de modelul AI pentru a stoca informațiile. Ori mai simplificat decât atât, cu cât valoarea FP (Floating Point) este mai mică, cu atât informația stocată pe memoria video a plăcii este mai compresată. Evident, ca în cazul oricărei metode de micșorare a datelor, se mai pierd informații pe parcurs. Aici apare partea cu NV care vine de la NVIDIA. Adică acest tip de model a fost optimizat ca să funcționeze eficient pe plăcile GeForce RTX cu un consum redus de resurse. Și pe măsură ce evoluează, modelele astea vor deveni din ce în ce mai eficiente.
Ce vreau să fac aici este să rulez pe PC-ul personal un LLM (Large Language Model), adică un model AI de tip deep-learning care știe să învețe pe baza informațiilor pe care i le dai. O să trântesc în el cam toate documentele oficiale de pe la producătorii de componente, ghiduri de review, fișe tehnice și orice material cu date exacte. Și pe măsură ce-l învăț tech o să îmi fie mult mai ușor să mă ajute la scris. În loc să stau să caut specificațiile unui produs, i le cer direct și-l pun să le strântească într-un tabel. Vreau să verific rapid o informație, știu sigur că vine dintr-o sursă sigură.
De ce nu folosești ChatGPT?
Știu că cei mai mulți vă întrebați de ce nu folosesc direct ChatGPT, iar motivele ar fi mai multe. În primul rând vorbim despre securitatea datelor, iar un LLM rulat local nu va putea scurge pe internet nimic. Plus că fără nevoia de conexiune la net voi putea să folosesc chatbot-ul și dacă pică netul. Mai există o chestie aici legată de natura meseriei. Când vine NVIDIA cu câte o lansare, creatorii de conținut primesc niște documentație care explică mai în detaliu chestii tehnice, ne oferă scenarii și sugestii de testare ca să putem explica mai bine diferențele, includ specificațiile în detaliu – tot ce-ți trebuie ca să te familiarizezi cu produsul. Numai că documentele astea sunt adesea sub un NDA (Non-Disclosure Agreement) ca să nu apară leak-uri și alte situații neplăcute.

Cu un chatbot local sunt protejat de orice pericol și documentul acela nu ajunge nicăieri în afara PC-ului meu. Plus că fiind materialele oficiale de la producător, cu informații și date tehnice corecte, pot oricând să-l întreb pe MarinakeGPT una-alta fără să trebuiască să mai verific de două ori. ChatGPT, Gemini și ceilalți boți disponibili online chiar te anunță că informațiile nu sunt mereu precise pentru că na, ăla săracu e un algoritm, nu are abilitatea să verifice informația și ia de bun ce găsește. Alt avantaj pe termen lung este că bot-ul personal nu va fi niciodată blocat după un abonament. Soluțiile comerciale deja încep să introducă tot felul de costuri, îți limitează accesul la funcții, ori îți oferă nenorocitele alea de credite de zici că ești la clămpănele.
Mai există și partea de personalizare, întrucât poți să îți înveți chatbot-ul să genereze răspunsuri pe un anumit ton: poate lucrezi într-un domeniu mai corporate unde trebuie să ai un limbaj de lemn, sau ești la polul opus și îți place să primești răspunsuri pe limba ta. Indiferent de cum îl vrei, așa ți-l înveți, iar chatbot-ul local poate căpăta personalitatea lui pe măsură ce ai răbdare și vorbești cu el. Iar dacă nu ai bani de un asistent personal sau vrei un ajutor la învățat, asta mi se pare una dintre cele mai tari utilizări ale inteligenței artificiale.
Partea tare este că poți să găsești modele din astea pentru orice tip de activitate. Aruncam un ochi pe blog-ul NVIDIA și-am găsit un AI care este foarte bun la scris de cod, astfel le sare în ajutor oamenilor care lucrează cu mii de linii de cod zilnic – mai obosești, îți mai scapă câte o greșeală. Așa doar ți-ai terminat treaba și-l lași pe bot să verifice. Iar dacă ești la început de drum, AI-ul te va ajuta să stăpânești mai bine multitudinea de comenzi. Asa face procesul de învățare mai ușor și încurajează oamenii autodidacți.
Teste practice
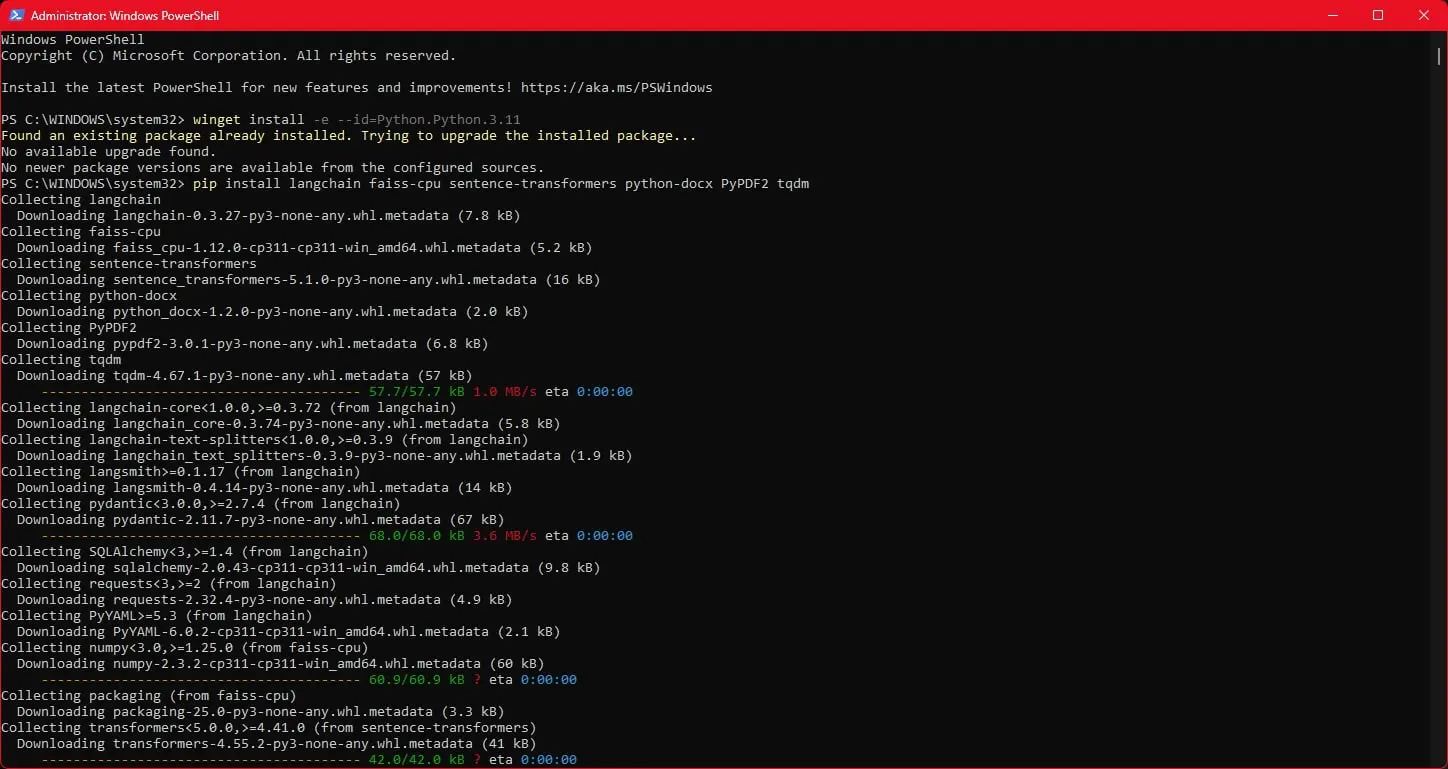
Bun, m-am pus la treabă și am descărcat LM Studio. Odată instalată aplicația, am descărcat pachetul gpt-oss-20b care are vreo 12GB în acest moment și am început să discutăm. Din fabrică el vine destul de chel, cu un minim de informații generaliste, însă știe să te ghideze foarte bine. Iar ca să îmi iasă treaba cu stocarea de documente din care să învețe informații am nevoie să mai instalez un framework de tip RAG (Retrieval-Augmented Generation).
Treaba asta este ceva mai complicată și implică să-ți bagi nasul puțin în Python, dar nu trebuie să știi mare lucru, ci doar să dai copy-paste la niște chestii în PowerShell-ul din Windows. E nevoie să facem asta pentru a crea un folder pe care LLM-ul local să-l știe drept librăria lui de informații și să se hrănească de acolo de fiecare dată când îi pun o întrebare. Tot setup-ul durează vreo 20-25 minute și poți folosi LLM-ul deja instalat în LM Studio pentru a-ți scrie codul de care ai nevoie. Odată ce-am trecut cu bine de tot mumbo jumbo-ul de cod am putut să trântesc documentația în folderul ei.
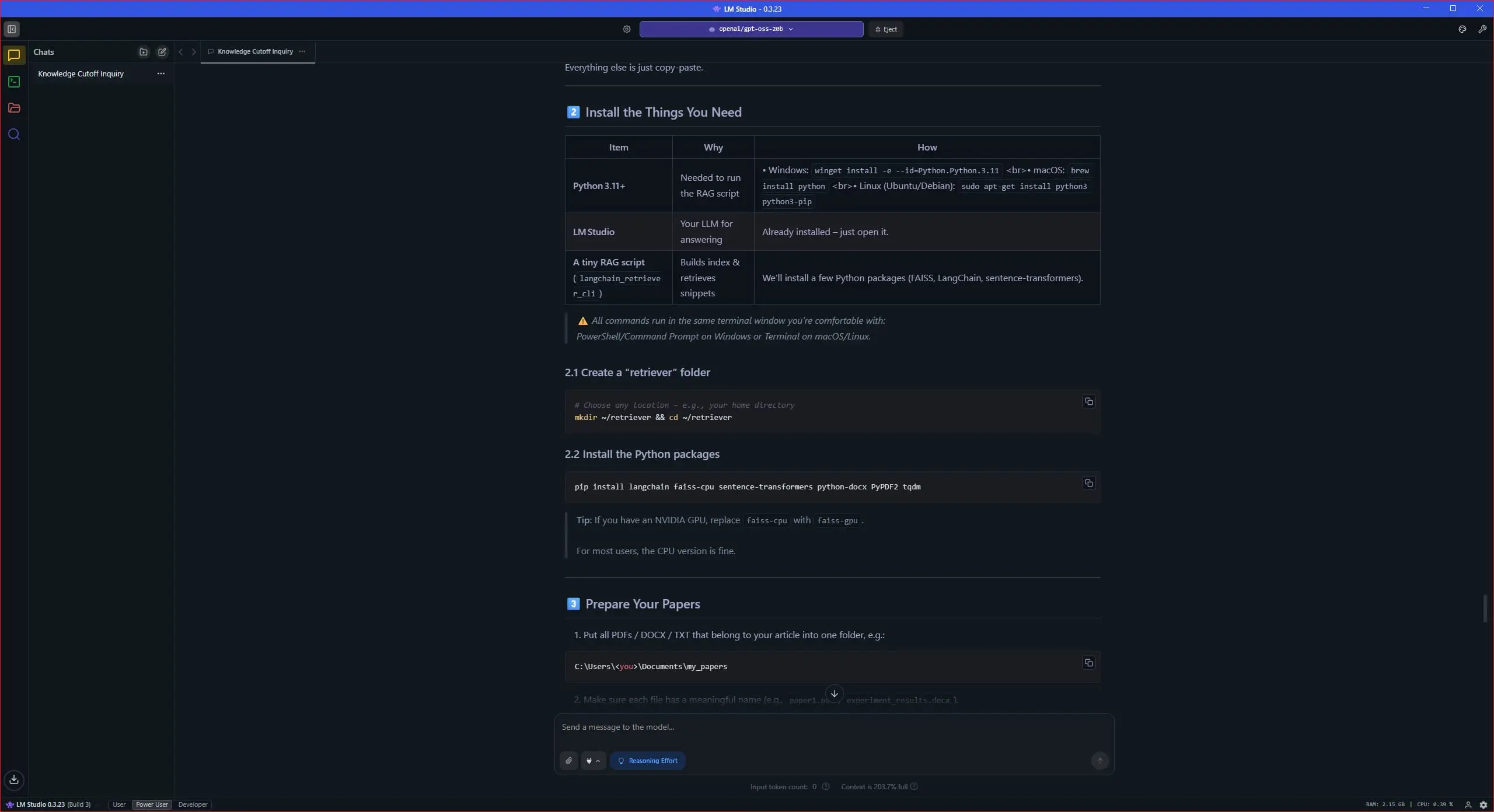
Și acum… momentul adevărului. Așa că am gândit două sarcini pentru MarinakeGPT. Prima este să-mi poată spune ce rezultate obține placa mea video în diferite jocuri pe care le-am testat, iar a doua este să-mi poată oferi specificațiile acesteia din reviewer’s guide-ul primit în perioada lansării.
Mai jos am lăsat și câteva capturi de ecran cu răspunsurile pe care mi le-a dat MarinakeGPT după ce l-am configurat:
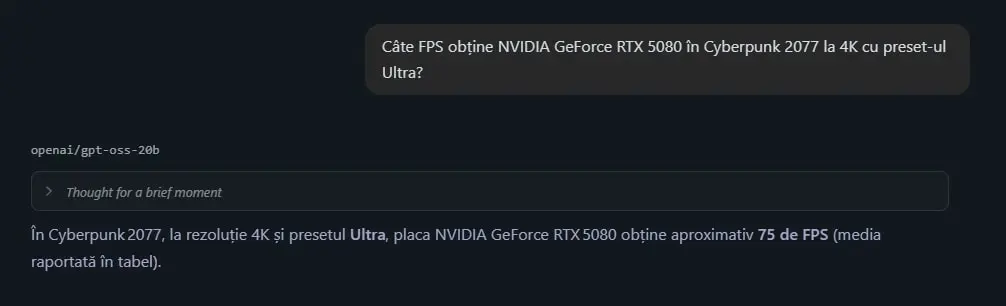
O chestie de urmărit aici este performanța, iar în cazul de față aceasta se măsoară în ceea ce LM Studio numește “tok/sec”, unde tok se referă la token, unitatea fundamentală de text pe care modelul o folosește ca să proceseze informație. În practică, pentru a determina performanța unui PC în sarcini AI trebuie să luăm în calcul mai mulți factori, precum TTFT (Time to First Token) care ne indică cât durează până începe generarea răspunsului, dar și complexitatatea modelului, care-n cazul nostru este de 20 de miliarde de parametri.

PC-ul meu dotat cu NVIDIA GeForce RTX 5080 a scos 51.88 tok/sec cu un timp de numai 0.73s până la primul token la un răspuns de 497 de token-uri. Asta ar fi considerat un rezultat destul de bun în termeni AI, indicând că am destul oomph cât să rulez acest LLM în condiții optime. Un răspuns lent ar fi pe la 25-30 tok/sec, iar plăcile precum GeForce RTX 5090 sau modelele enterprise pot duce lejer peste 100 tok/sec în anumite modele.
Concluzie
Ce-am învățat din experimentul de astăzi este că inteligența artificială a devenit mai accesibilă ca niciodată; evident, dacă-ți permiți hardware-ul care să îi ofere un mediu propice de creștere. Mi s-a părut că totul a fost destul de straight-forward, fără să-mi prind nasul în nimic. Am fost puțin confuz la partea cu Python, dar de bine de rău mă descurc în Terminalul din Linux, deci am fost oarecum familiar. Iar odată setat noul bot AI, chiar pot să-mi ușurez viața când scriu.
Acum nu mai este nevoie să sap prin documentele cu rezultatele de la fiecare sesiune de benchmark, la fel cum nici nu trebuie să mai stau să caut manual la întrebări d-astea de mi le mai pun când lucrez, gen “De la ce vine prescurtarea de NVIDIA DLSS?”. Are MarinakeGPT răspunsurile oficiale, iar eu trebuie doar să-l iau la întrebări ca să mai verific odată informațiile dintr-un document. Plus că mai știe să corecteze și typos în Limba Română, deci nu mai vedeți atâtea greșeli în materialele mele.
Știu, știu, lucrez într-un domeniu creativ și AI-ul amenință să omoare o arie a acestui domeniu. Doar că mi se pare că aș fi ipocrit să spun că e o prostie din poziția de jurnalist tech, plus că aș da cu piciorul unui mod foarte simplu de a-mi ușura munca. Iar dacă așa voi scrie mai mult și mai bine, de ce să nu profit?
Material realizat cu sprijinul NVIDIA.